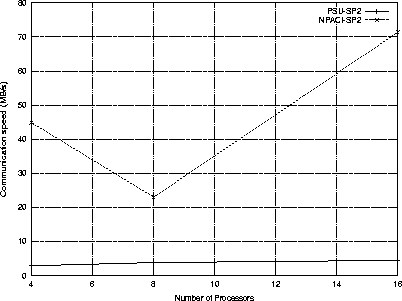
The Penn State SP2 (mcnally.cac.psu.edu) has 32 POWER2 Super Chip (PSC model 390) processors with 128 MBytes of memory on each processor running at 66 Mhz and are capable of a peak performance of 250 MFLOPS each. It is capable of a peak bi-directional data transfer rate of 35 MB/second between each node pair.
The NPACI SP2 (sp.npaci.edu) has 128 thin node POWER2 Super Chip (P2SC) processors with 256 MBytes of memory on each processor running at 160 Mhz and are capable of a peak performance of 640 MFLOPS each. It is capable of a peak bi-directional data transfer rate of 110 MB/second between each node pair.
| P | N | Comm | Calc | Total | Mflops/P | MB/s | ||
|---|---|---|---|---|---|---|---|---|
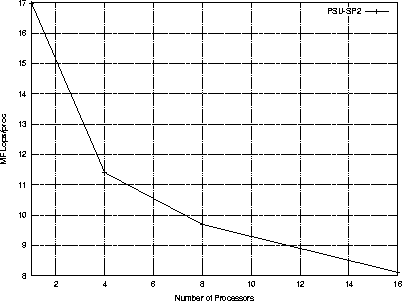
| 1 | 400 | 0.14 | 3.63 | 3.77 | 16.99 | - | 100 | - |
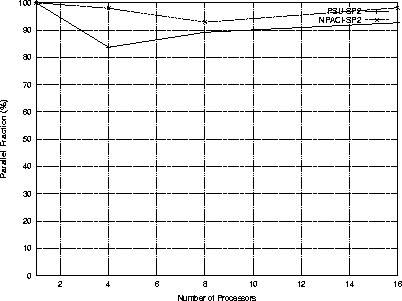
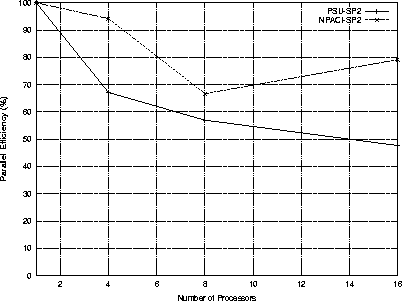
| 4 | 800 | 1.76 | 3.85 | 5.61 | 11.40 | 83.7 | 67.1 | 2.92 |
| 8 | 1100 | 2.75 | 3.48 | 6.24 | 9.69 | 89.2 | 57.0 | 3.85 |
| 16 | 1600 | 4.59 | 3.31 | 7.90 | 8.11 | 92.7 | 47.7 | 4.49 |
| P | N | Comm | Calc | Total | Mflops/P | MB/s | ||
|---|---|---|---|---|---|---|---|---|
| 1 | 400 | 0.050 | 0.839 | 0.889 | 71.98 | - | 100 | - |
| 4 | 800 | 0.115 | 0.828 | 0.943 | 67.84 | 98.0 | 94.2 | 44.86 |
| 8 | 1100 | 0.460 | 0.800 | 1.260 | 48.00 | 92.9 | 66.7 | 23.05 |
| 16 | 1600 | 0.289 | 0.834 | 1.123 | 57.00 | 98.2 | 79.2 | 71.35 |
| 32 | 1600 | 0.729 | 0.872 | 1.601 | 41.24 | 97.6 | 57.3 | 60.87 |
| P | N | Comm | Calc | Total | Mflops/P | ||
|---|---|---|---|---|---|---|---|
| 1 | 400 | 6.35 | 5.36 | 11.73 | 5.46 | - | 100 |
| 8 | 1100 | 8.06 | 5.15 | 13.26 | 4.57 | 97.2 | 83.6 |
| 16 | 1600 | 10.62 | 5.39 | 16.07 | 3.99 | 97.5 | 73.0 |
| 32 | 2300 | 8.67 | 5.81 | 14.52 | 4.55 | 99.4 | 83.4 |
| Case | P | HPF Timing | MPI Timing | |
|---|---|---|---|---|
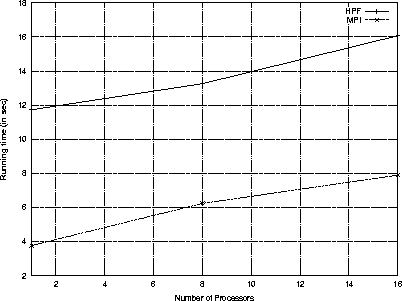
| 1 | 1 | 11.73 | 3.77 | 311 |
| 2 | 4 | - | 5.61 | - |
| 3 | 8 | 13.26 | 6.24 | 213 |
| 4 | 16 | 16.07 | 7.90 | 203 |
| 5 | 32 | 14.52 | - | - |